【固定した記事】デジタルアーカイブシステムの技術ブログへようこそ
デジタルアーカイブシステムの技術に関するブログです。特に、OmekaやIIIF、TEIなどに関する記事を執筆します。
Omekaの使い方に関する情報は、以下の記事にまとめています。
Omeka.net(Classic)の使い方に関する情報は、以下の記事にまとめています。
カテゴリ「IIIF」の記事は以下です。
カテゴリ「TEI」の記事は以下です。
その他の記事については、カテゴリなどからご確認ください。
Nuxt.jsとNext.jsの比較
Nuxt.jsとNext.jsは、どちらもJavaScriptのフレームワークで、Vue.jsとReact.jsの上に構築されています。それぞれのフレームワークには独自の利点がありますが、Nuxt.jsがNext.jsに比べて優れているとされる点をいくつか挙げます。
Vue.jsの利点: Nuxt.jsはVue.jsをベースとしているため、Vue.jsの利点を引き継いでいます。Vue.jsは、コンポーネントの構造がシンプルで、学習曲線が緩やかであることが評価されています。
ディレクトリベースのルーティング: Nuxt.jsは、ディレクトリ構造を使ってルーティングを自動生成します。これにより、開発者はルーティング設定を手動で行う必要がなくなり、開発効率が向上します。
Vuexの統合: Nuxt.jsでは、Vuex(Vue.jsの状態管理ライブラリ)がデフォルトで統合されています。これにより、状態管理が容易になります。
ミドルウェアのサポート: Nuxt.jsでは、ミドルウェアを利用してルートやページにカスタムロジックを追加できます。これにより、開発者はアプリケーションの振る舞いを簡単にカスタマイズできます。
モジュールシステム: Nuxt.jsにはモジュールシステムがあり、コミュニティで開発された機能を簡単に追加できます。これにより、開発者はアプリケーションの拡張性を向上させることができます。
ただし、どちらのフレームワークが優れているかは、プロジェクトの要件や開発者のスキルセット、好みによって異なります。Next.jsもReact.jsのエコシステムやサーバーサイドレンダリング(SSR)、静的サイト生成(SSG)などの機能を持っており、多くの開発者に支持されています。最終的には、どちらのフレームワークがプロジェクトに適しているかを慎重に検討することが重要です。
正規URLとは? (canonicalUrl)
canonical URLとは、同じコンテンツを指す異なるURLが存在する場合に、その中から1つの「正規」なURLを選ぶことです。これは検索エンジンがコンテンツの重複を防ぎ、ウェブページの検索順位に悪影響を与えることなく、ウェブページの重要度を正確に評価できるようにするために使用されます。
例えば、以下のようなURLがあったとします。
- http://example.com/page
- http://www.example.com/page
- https://example.com/page
- https://www.example.com/page
これらのURLはすべて同じコンテンツを指しているとしても、検索エンジンはそれらを異なるページとして扱うことがあります。canonical URLは、HTMLの<head>セクション内に<link rel="canonical" href="https://www.example.com/page" />のような形で指定されます。この場合、指定されたURLが正規のURLとして検索エンジンに認識されます。
「Google ドライブでエラーが発生しました。」が生じた時の対処方法:共有ドライブのゴミ箱を空にするスクリプト
概要
共有ドライブに対して大量のファイルを作成した際、以下のように「Google ドライブでエラーが発生しました。」が表示され、ファイルを保存できなくなる事象に出会いました。

上記の原因として、以下に示す共有ドライブの制限に引っかかったことが考えられます。
https://support.google.com/a/answer/7338880?hl=ja
共有ドライブに保存できるアイテム数の上限 共有ドライブに保存できるアイテム数は最大 40 万個です。これにはファイル、フォルダ、ショートカットが含まれます。
1 日のアップロードの上限 個々のユーザーがマイドライブおよびすべての共有ドライブにアップロードできるのは、1 日あたり 750 GB までです。
2つ目の「1日のアップロードの上限」に引っかかってしまった場合には、1日待つほかないと思います。
一方、1つ目の「共有ドライブに保存できるアイテム数の上限」について、不要なファイルを削除することで対応することができます。
ただし、単にファイルを削除しただけでは、それらがゴミ箱に残ってしまい、(おそらく)先の制限を解除することができません。そこで、共有ドライブのゴミ箱を空にするスクリプトを探したところ、以下の記事に辿り着きました。
以下、上記で紹介されているスクリプトの使用方法について説明します。これにより、先述した「共有ドライブに保存できるアイテム数の上限」に引っかかってしまった際、その制限を解除することができます。
共有ドライブのゴミ箱を空にするスクリプトの実行方法
以下のスクリプトをコピペして利用します。
const driveId = "<共有ドライブのID>"; function myFunction() { var optionalArgs={driveId, 'includeItemsFromAllDrives':true, 'corpora': 'drive', 'supportsAllDrives': true, 'q':'trashed = true' } while(true){ var trashed=Drive.Files.list(optionalArgs).items; console.log("削除対象のファイルサイズ", trashed.length) for(var i=0;i<trashed.length;i++){ //console.log(i, trashed[i].id) try { Drive.Files.remove(trashed[i].id, {'supportsAllDrives':true}) } catch (e){ //console.log({e}) } } if(trashed.length == 0){ break } } }
まず、以下のURLにアクセスしてください。
https://script.google.com/home
そして、下図に示す、「新しいプロジェクト」をクリックします。

先のスクリプトをコピペしてください。コピペ後、一行目の「driveId」を変更し、画面上部の「保存」ボタンを押してください。

次に、サービスを追加します。「サービス」から「Drive API」を追加してください。

その後「実行」ボタンを押します。

初回は承認が求められます。

以下に示すように、100件ずつ削除されていきます。

一定時間が経過すると、以下のようにエラーが発生します。その場合には、再度「実行」ボタンを押してください。

まとめ
よりよい解決策があるかもしれませんが、「Google ドライブでエラーが発生しました。」等でお困りの方の参考になりましたら幸いです。
追記
2022.05.06
GASでは、スクリプトの実行時間が6分間という縛りがあるそうです。
https://developers.google.com/apps-script/guides/services/quotas#current_limitations
そのため、上記スクリプトを5分または10分おきに実行することで、ゴミ箱を自動的に空にすることができます。
具体的には、以下のように、トリガーを選択して、「トリガーを追加」ボタンをクリックします。

そして以下のように、「時間主導型」「分ベースのタイマー」「X分おき」を選択します。

参考になりましたら幸いです。
Google Colabを用いたgcv2hocrの実行例:Google Vision APIを用いた透明テキスト付きPDFファイルの作成
概要
gcv2ocrは、Google Cloud Vision OCR出力からhocrに変換して、検索可能なpdfを作成するリポジトリです。
https://github.com/dinosauria123/gcv2hocr
今回、上記リポジトリをGoogle Colabで実行するノートブックを作成しました。
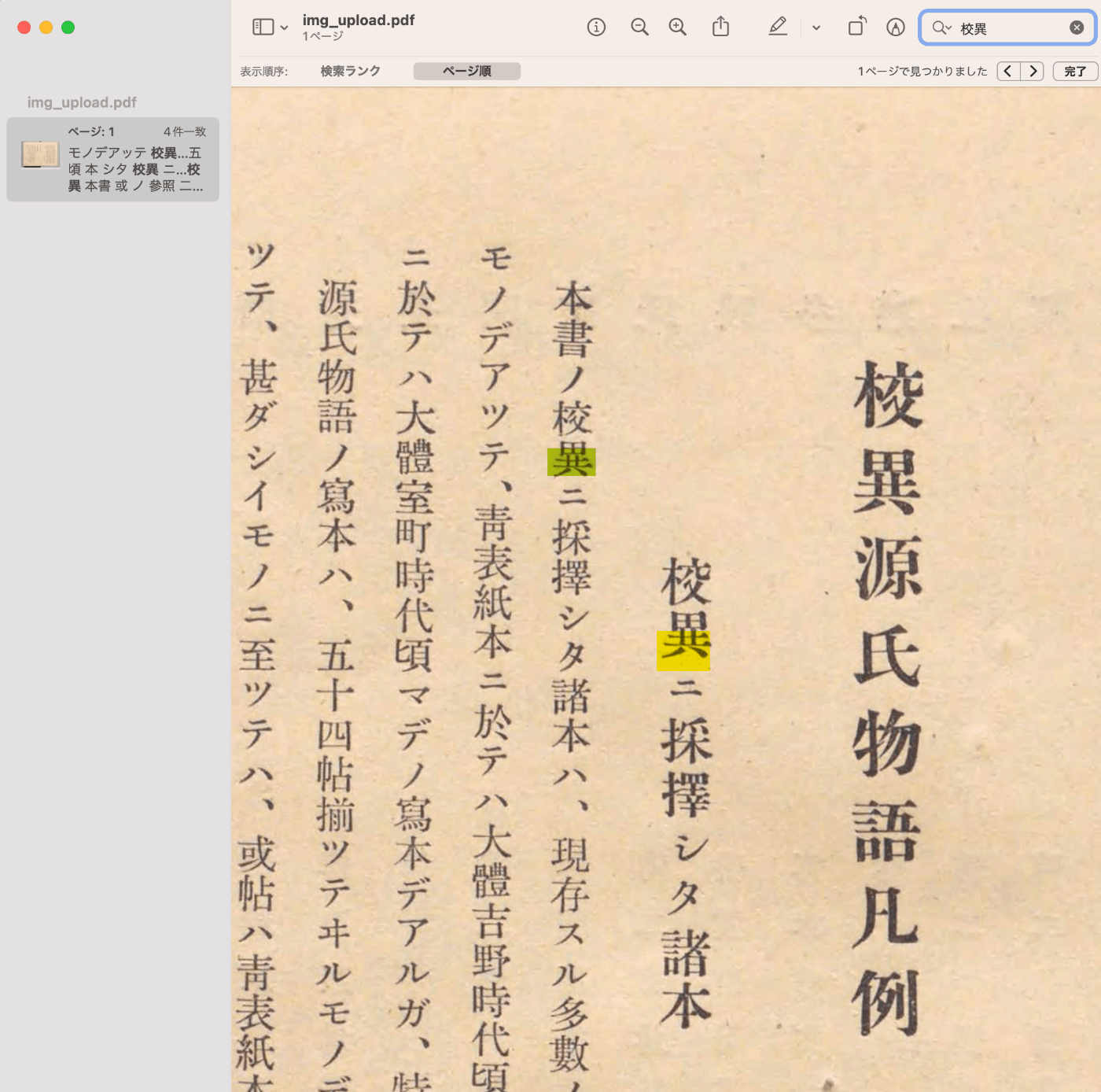
以下のように、検索可能なpdfファイルを作成することができます。
使い方
以下のノートブックにアクセスします。
まず、Google Cloud Vision APIを使用するためのAPIキーを取得します。以下の記事などが参考になります。
https://zenn.dev/tmitsuoka0423/articles/get-gcp-api-key
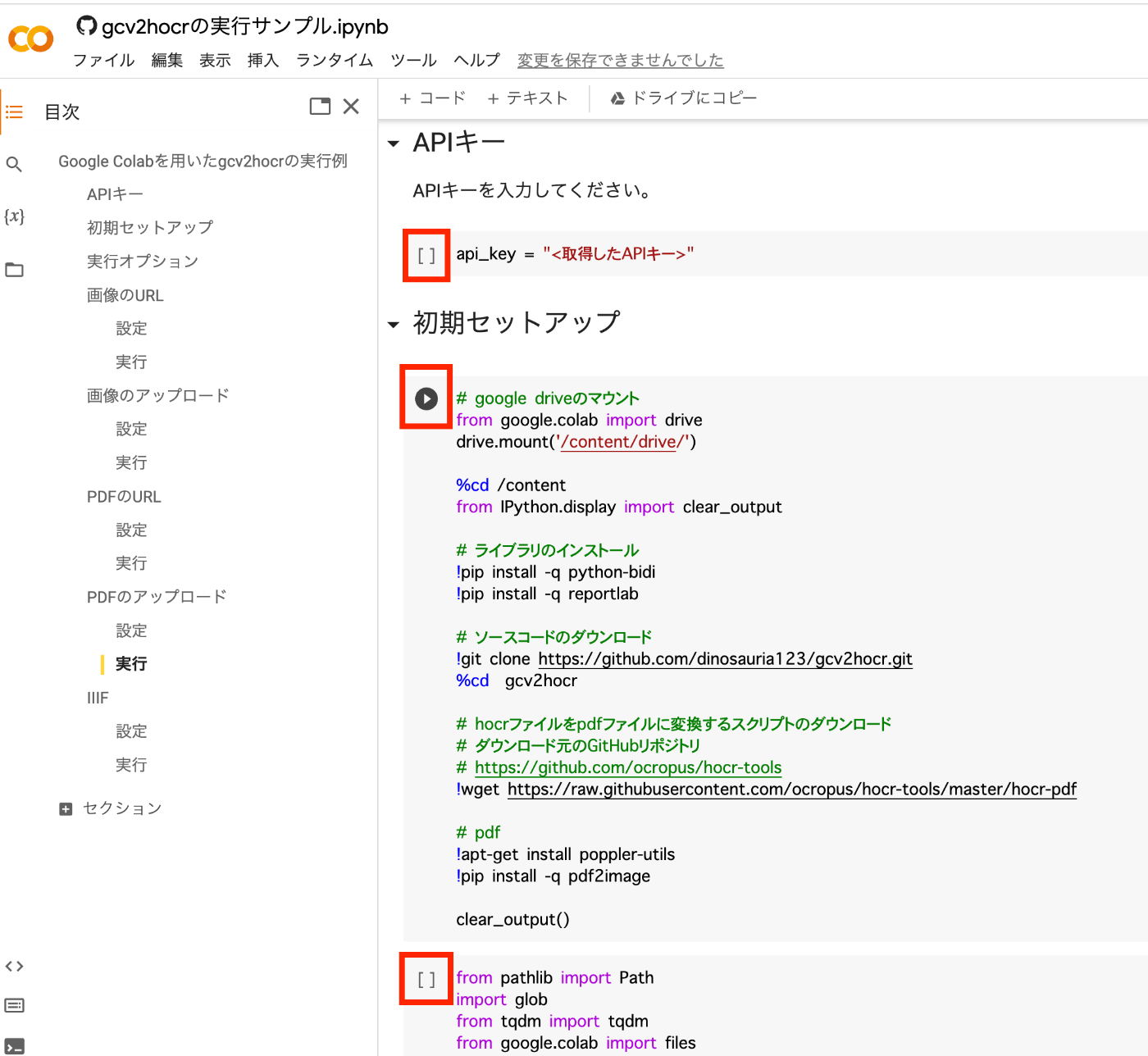
APIキーを入力したら、以下の初期セットアップに関する3つの再生ボタンを押します。
その後は、以下に示す実行オプションから、適切なものを選択します。
- 画像
- 画像のURL
- 画像のアップロード
- PDF
- PDFのURL
- PDFのアップロード
- IIIF
- IIIF
例えば、「画像のURL」を指定する場合、以下に示す「設定」と「実行」の2つの再生ボタンを押します。

実行後、PDFファイルがダウンロードされます。また、認識結果等が出力されるパスが表示されます。
まとめ
gcv2ocrやhocr-toolsなど、便利なツールを開発してくださった方々に感謝いたします。
Google Colabを用いたGoogle Drive上のファイルの削除方法
Google Drive上のファイルをGoogle Colabを用いて削除する例を示すノートブックを作成しました。Google Drive上に不要なファイルを大量に作成してしまった際など、ご活用いただけますと幸いです。
Google Colabを用いたNDLOCRアプリのVersion 2を作成しました。
概要
Google Colabを用いたNDLOCRアプリを作成し、以下の記事で紹介しました。
今回は、上記ノートブックの改良版であるVersion 2を作成しましたので紹介します。以下からノートブックにアクセスいただけます。
https://colab.research.google.com/github/nakamura196/ndl_ocr/blob/main/ndl_ocr_v2.ipynb
特徴
複数の入力形式に対応しました。以下のオプションを使用できます。
- 画像
- 単一の画像ファイルのURLを指定する場合
- 単一の画像ファイルをアップロードする場合
- 複数の既にダウンロード済みの画像ファイルを対象にする場合(Sigle input dir mode)
- 複数の既にダウンロード済みの画像ファイルを対象にする場合(Image file mode: 単体の画像ファイルを入力として与える場合)
- PDF
- 単一のPDFファイルのURLを指定する場合
- 単一のPDFファイルをアップロードする場合
- 単一の既にダウンロード済みのPDFファイルを対象にする場合
- 複数の既にダウンロード済みのPDFファイルを格納したフォルダを指定する場合
- IIIF
PDFファイルやIIIFマニフェストファイルの入力をサポートします。また、Version 1では事前にGoogle Driveに画像ファイルをアップロードする必要がありましたが、Version 2では画像ファイルのURLの指定や、アップロードフォームによる登録機能を提供しています。
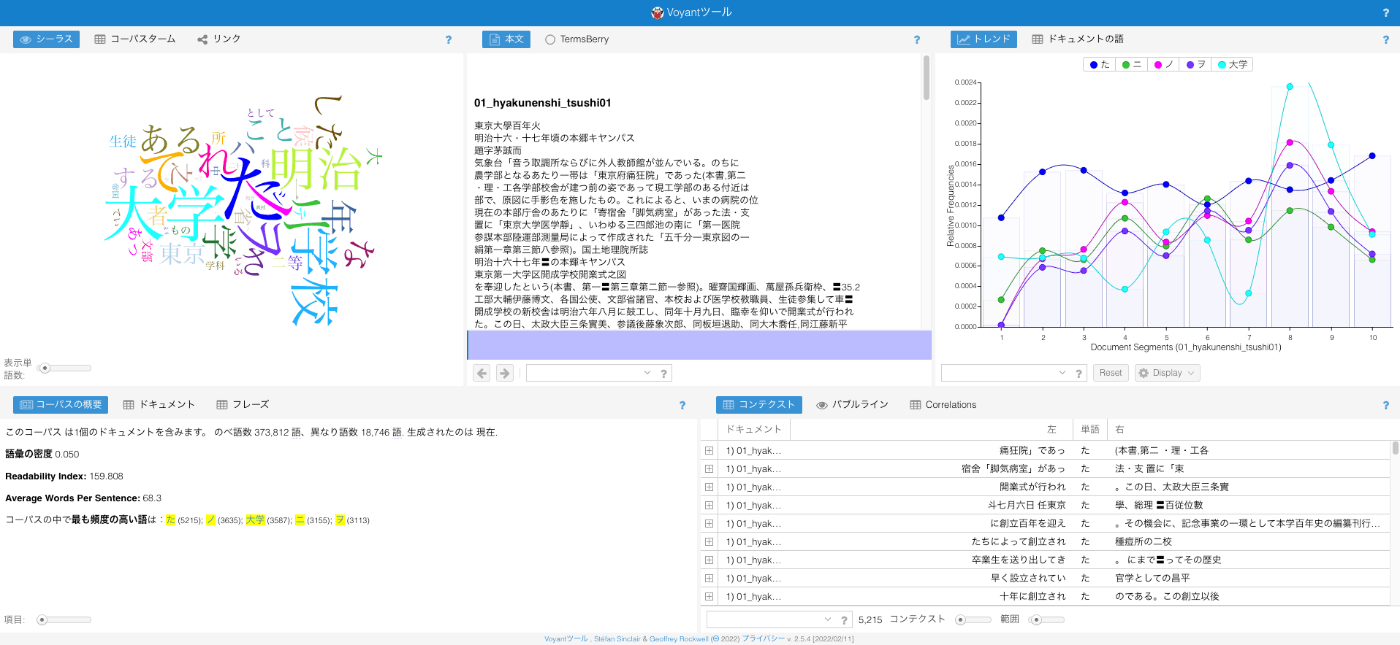
さらに、上記のいくつかのオプションにおいて、実行後に推論結果をマージしたテキストファイルをダウンロードする機能を提供します。ダウンロードしたテキストファイルをVoyantツールなどの他のアプリケーションに使用することができます。(なお本格的な分析にあたっては、認識結果の修正やトークナイズの方法など、各種調整が必要です。)
使用方法
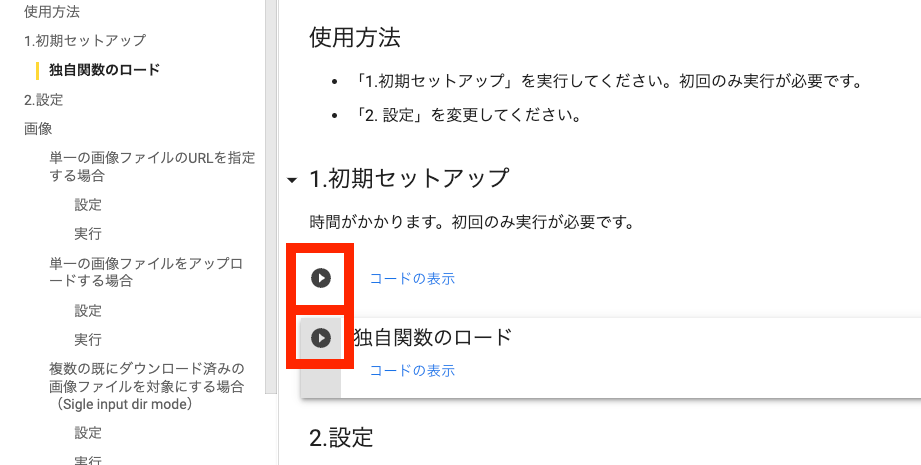
1.初期セットアップ
以下に示す2つの実行ボタンを押してください。Googleドライブのアクセス許可が求められるので、許可してください。
2.設定
上述したオプションから、目的に応じたものを選択してください。各オプションに付与されたリンクをクリックすると、当該オプションの設定画面に遷移します。
実行後
実行後は、以下のように、出力フォルダが表示されます。設定において選択したprocessの値が「@(アットマーク)」とともにフォルダ名に付与されます。また既に出力フォルダが存在する場合には、フォルダ名の末尾に実行時間に基づくIDが「_(アンダーバー)」とともに付与されます。
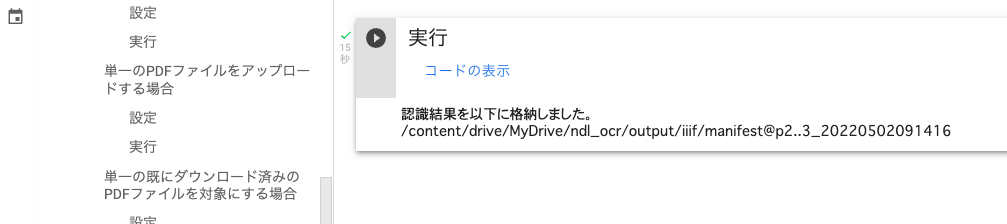
また単一のファイルを処理するオプションを選択した場合、実行後、以下のようにテキストファイルがダウンロードされます。
まとめ
NDLOCRアプリの利用にあたって、参考になりましたら幸いです。
Nuxt 2を用いたMirador 3の使用例を紹介するGitHubリポジトリの修正
Nuxt 2を用いたMirador 3の使用例を以下のGitHubリポジトリで紹介しています。
https://github.com/nakamura196/nuxt-mirador
ただ上記のリポジトリにおいて、production環境において不具合が生じることがわかりました。具体的には、ページ遷移後にMiradorの表示が崩れてしまう不具合です。

送っていただいたissue
https://github.com/nakamura196/nuxt-mirador/issues/1
このissueについて、さらに不具合を修正したPull requestも送っていただきました。
https://github.com/nakamura196/nuxt-mirador/pull/2
具体的には、以下に示すように、beforeDestroyでunmountする必要がありました。
https://github.com/nakamura196/nuxt-mirador/pull/2/files
自分では不具合の解消方法が分かりかねたので、大変助かりました。
Nuxt(Vue)におけるMirador 3の使用において、参考になりましたら幸いです。